
Note: This article is Chinese-only.
上一篇两年前的文章 记 容器编排工具 k3s + Rancher 环境的搭建 记录了 外置 mysql 数据库、运行在 Azure 云上的 k3s 集群,以及方便的集群管理工具 Rancher 的安装与配置过程。
对于家中(寝室?学校/实验室?)有自建 NAS 、树莓派/服务器等 Homelab 设施,以及在多个云服务商部署有云服务器这种更为常见场景的我来说,为了设法充分利用这些资源,我在这之后又探索了各种能够实现分布式高可用 k3s 集群的搭建。
对于这种应用场景下的集群,为了保证稳定和可靠性,要反复斟酌的主要有这几个点:
- 如何为处于不同网络环境下的机器完成互联?
即使是分布在不同的运营商,让拥有公网 IP 的云服务器之间互联也很容易(例如用 WireGuard 组网,甚至不组网直接使用 IPv6 亦可)。但如何将他们和 Homelab 里没有公网 IP 的机器互联呢? - 在可能出现延迟突升甚至机器掉线的情况下,使用 k3s 作为集群服务部署工具,该选取哪种 datastore 方案(嵌入式 SQLite / 嵌入式 Etcd / 外置 Etcd 集群 / 外置 Mysql Postgres)呢?
最终经过多次反复试错和尝试,我的部署方案停留在 使用 自建 MariaDB Galera 集群的多 Server 节点高可用部署 和 通过 Tailscale NAT 穿透 建立跨云内网实现跨云 k3s 集群。本文在 k3s 跨云的各种坑中摸爬滚打后,给出如下的能够较完美运行的配置方案供大家参考。
那么我们就开始吧☺️
WireGuard 与 Tailscale
在正式的部署流程前,先给大家简要介绍下 WireGuard VPN 和 Tailscale 这个强大的组网工具。
WireGuard 是一个用于替代 OpenVPN、L2TP/IPsec 这类传统 VPN 的高性能、现代化且安全的 VPN 协议(官网是这么描述的),它与这些传统 VPN 的主要区别有:
- WireGuard 在保证核心功能 “加密隧道” 实现的同时切割掉了许多不必要的功能,因此它相当的简洁(代码只有几千行),还有着非常简单的配置步骤
- WireGuard 可以运行在内核态,避免了与用户态之间来回切换,因此速度非常快,且可以支持很高的带宽
- WireGuard 没有 Server/Client 之分,连线的两端地位是对等的,因此非常适合用来进行各种拓扑组网
知乎 上有一篇文章详细介绍了 WireGuard 是如何对传统 VPN 进行精简化的;后面我也会看看源码学习学习,毕竟我对能简洁优雅地实现核心功能的东西相当感兴趣。
Tailscale 是一个基于 Wireguard 实现的 mesh 网络构建器。它大致是通过一个集中式 control plane 记录与分发不同节点之间的 wireguard 连接配置,以及一些灵活的打洞黑科技来实现的。
对于大多数用户来说,Tailscale 的主要功能即通过搭建 mesh vpn,将处于不同网络的设备连接在同一个网络下。
使用 Tailscale 为集群跨云互联组建虚拟内网
首先要在这里说明的一点是:k3s 在较新版本中自带有 Tailscale 支持(详见 Distributed hybrid or multicloud cluster),但是并不建议使用:
- 对于每个节点,用于 k3s 网络基础设施维护的 flannel 会创建一个 cidr 子网。
比如说节点 A 下的所有 pod 会分配 10.42.0.0/16 的地址,节点 B 下的所有 pod 会分配 10.42.1.0/16 的地址。
Tailscale 需要 为每个节点创建一个 Subnet Router 来完成 跨节点间 pod 网络的互联 (例如 10.42.0.31 <-> 10.42.1.56)。免费版只有一个 router 的额度,自建 Headscale 的话稳定性可能得不到较好的保障,因此不考虑自建。 - 这个方案需要让 k3s 接管该节点的 Tailscale 的运行,虽然可以传自定义参数进去,倘若在集群运行时对 Tailscale 进行配置的话,可能玩着玩着集群就炸了😊
其次还要再提醒一下,本文的方案是 在每个节点上都跑 Tailscale 来组网,但在经过一段时间的运行后发现,就算所有设备均始终处在校园网这个大内网中,Tailscale 也并不是随时都能打通直连的喔,特别是在 类似于 site2site 拓扑 的网络架构时,有较小几率出现一边只有一台机器能够直连而其他机器走代理的现象,V 站上也存在这样的讨论(可以搜搜,地址嚒我不记得了)。这种情况就建议在本城开个 derp 做个最低延迟的中转咯;要不就 site2site,参考官方文档 Site-to-site networking。当然,这个也需要两个或以上的 Subnet Router。
网络基础设施配置
网络基础设施的准备主要分为两个方面:搭建分布式网络,以及大陆用户绕不开的完整互联网访问。
先使用下面的命令在各个节点上安装好 Tailscale:
curl -fsSL https://tailscale.com/install.sh | sh然后执行 tailscale up,点击提示中的链接登录即可。
集群中所有节点均安装完成后,可以进入 Tailscale Admin Console 为节点配置各自的 IP。
P.S. 这里出现了第一个坑,注意 不要使用 Exit Node,这将会导致 flannel 10.42.0.0/16 所有的包都丢被到出口节点上,就算加上 --exit-node-allow-lan-access flag 也行不通(因为 10.42.0.0/16 并不在 Tailscale 定义的 Lan 段内)。
由于跑的许多服务都需要例如 Google API 等服务的支持,我之前在大陆内单台服务器的做法都是直接使用出口节点将包转发到境外机器上。
对于现在的部署方案,这种做法就行不通咯。截止目前,我暂时还没有找到能够正确部署这个路由规则的方法(只要这句话还在本文当中,就说明我还没能有时间来研究😭)。此外,Tailscale 打洞的难度会随着两个 peer 间 hop 数量的增加而增加,因此使用 openwrt 软路由 + openclash 透明代理的方式不仅会为 Tailscale 添堵,而且会让机器对软路由的正常工作状态产生强依赖性,似乎也不太可取。
最后,我似乎已经找到目前来说最佳的替代方法:在境外机器上部署 dns 服务器作中继杜绝 dns 污染,以及 仅对内网地址开放 http 或 socks proxy 供境内服务器代理流量。我在 plamnet 中使用的是 AdGuard Home + v2ray 多机器负载均衡,能够非常稳定地提供基础的网络服务。
使用自建外置 MariaDB Galera 集群为 k3s 提供 datastore
Galera 是 Codership 公司为 Mysql 开发的 多主集群插件。MariaDB 在 10.4 版本后提供其官方支持,因此我便计划从 Mysql 迁移至 MariaDB。
通过网上资料的查找,国内使用 Galera 方案的人好像有点少啊。
你也许会疑惑,etcd 作为 kubernetes 原生 datastore 方案,那为什么不直接在 k3s 中使用呢?(当然是因为懒,学不动啦
因为对于我这种非专业运维来说,Mysql 已经用了很多年了,比 Etcd 熟悉得多,挂了能更迅速找到问题并及时解决;就算解决不了,Mysql 数据库的备份恢复易如反掌,能在较短时间恢复集群。
其次,新搭好的这个 Mysql(MariaDB) 集群 还可以用来存其他生产应用的数据,为它们提供数据库 高可用+多地备份 的特性,而这正是我从中学时代就想要得到的方案。
由于 datastore 作为 k3s 集群的核心,这里特地标明几个要点,其关系着搭建的集群是否能稳定使用(而不是浪费大量没必要的时间来折腾 ⚠️ :
- 经过网上大量博客、笔记和论坛资料的调研,我得到的结论是 k3s + 由云服务商提供的 MySQL 服务 能够最有效的避免集群宕机。
- Galera 集群搭建的主要目的为数据库备份,其次为高可用性。由于分布式数据库集群容易出现冲突的问题,严重的话可能会使整个数据库不可用,因此我的方案 不是在所有 k3s master 节点上安装 MariaDB,而是 选取几个网络延迟低、运行稳定的服务器安装 + 使用 TCP 负载均衡器做 Failover 来固定频繁读写的节点,从而尽量避免冲突问题的发生。
- Galera 集群至少需要三个节点;若只有两个节点时需要额外的配置才能保证其中一个节点掉线时集群还能正常运行,因此这里以三个节点为例。
数据库迁移
P.S. 这个环节非必须。
如果你跟我一样准备从 单节点 Mysql 迁移至 MariaDB Galera 集群,虽然很简单,但有几点提示可能会有些许帮助:
数据迁移前务必在 k3s 集群的 所有节点 上停止 k3s/k3s-agent。
然后可以准备导出数据库了。我习惯在集群中使用 phpmyadmin,在浏览器中就能很方便地导出下载单个数据库至 sql 文件并导入。
当然,如果你没有 phpmyadmin,也可直接使用 mysqldump 工具进行导出。
要注意的一点是,如果你是从 Mysql-5 迁移至 MariaDB-10 (对应 Mysql-8 的 API),因为版本兼容问题,在集群安装配置完成后,数据库导入前需要打开导出文件作如下更改:
utf8mb4_0900_ai_ci替换为utf8_general_ciutf8mb4替换为utf8
MariaDB 安装与集群配置
以下的命令均在 root 权限下执行。
安装前确保本地 Mysql 服务器已关闭:
systemctl stop mysql
systemctl disable mysql在所有节点上执行:
apt install mariadb-server mariadb-client mariadb-backup galera-4 注意:需要保证所有机器上的 mariadb-server 版本是相同的,否则在导入 redo log 时会报错。
安装指定版本的 mariadb-server 可参考官方提供的脚本来更新软件包仓库。例如给 Ubuntu 22 更新到 10.11.8 版本的 mariadb-server:
curl -LsS https://r.mariadb.com/downloads/mariadb_repo_setup | sudo bash -s -- --mariadb-server-version="mariadb-10.11.8"打开 /etc/mysql/mariadb.conf.d/ 文件夹,根据下面叙述仿照着更改 60-galera.cnf 配置文件:
[galera]
# Mandatory settings
wsrep_on = ON
wsrep_provider = /usr/lib/galera/libgalera_smm.so
wsrep_cluster_name = "carton.plam"
wsrep_cluster_address = gcomm://100.120.32.65,100.120.3.9,100.120.16.65
binlog_format = row
default_storage_engine = InnoDB
innodb_autoinc_lock_mode = 2
# Allow server to accept connections on all interfaces.
bind-address = 100.120.32.65
# Optional settings
#wsrep_slave_threads = 1
#innodb_flush_log_at_trx_commit = 0
wsrep_node_name = coord.plam.toay
wsrep_node_address = 100.120.32.65简要描述几个重要的:
- wsrep_provider wsrep 为 Galera 4 核心组件,确保这个 provider 动态链接库存在
- wsrep_cluster_address 在这里补充上 MariaDB Galera 集群 中所有节点的 Tailnet IP 地址
- bind-address 仅在 Tailnet 地址监听连接
所有节点均配置完成存盘退出后,在其中一个节点上执行 galera_new_cluster 来初始化集群。
MariaDB 会自动启动,等待命令成功退出后可 mysql -u root 通过 SQL 查询状态来检查集群节点数量:
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_cluster_size';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 1 |
+--------------------+-------+
1 row in set (0.001 sec)集群节点数为 1,表明集群已创建成功,且当前节点已成功加入。
此时再在其他节点启动 MariaDB 即可自动加入集群:
systemctl enable mariadb
systemctl restart mariadb然后再次通过 SQL 查询状态,可观察到与节点数相同的正确集群大小。至此,datastore 已为 k3s 准备完成。
部署 k3s 至集群
配置好网络和 datastore 后,可以正式开始 k3s 的安装了。
由于 datastore 只是从 Mysql 切换至同类的 MariaDB,故 k3s 的安装配置与上篇文章几乎完全一致,故这里不再给出详细安装流程。
需要留意的一点是,现在集群使用 Tailscale 作为其网络基础,因此需要在 配置并初始化集群中所有的节点后 在每个节点 (包括 k3s 和 k3s-agent) 的启动参数中添加一项 --flannel-iface tailscale0 来指定 flannel 的接口。
初始化集群前不要添加这个参数,会导致 Waiting for CRD helmchartconfigs.helm.cattle.io to become available 从而无法正常初始化集群。
连接集群至 Rancher 实现远程可视化管理
P.S. 同样地,这个环节非必须。
如果你和我一样习惯使用 Rancher 来管理 kubernetes 集群,可以从 Rancher Web 界面添加导入集群,然后复制粘贴命令到 control-plane 节点终端中执行,然后回到 Rancher 等待集群状态 Ready。
在此过程中可通过 sudo kubectl get pod -n cattle-system 命令查看 cattle cluster agent 的状态。若 pod 反复重启,然后在日志中遇到 pod 内 dns 不能正常解析的错误,可以尝试修改 deployment 的 dnsPolicy 为 ClusterFirst:
修改前:
NAME READY STATUS RESTARTS AGE
cattle-cluster-agent-569cc46d9c-66pdb 1/1 Running 0 83s
cattle-cluster-agent-569cc46d9c-pkljj 0/1 Error 2 (40s ago) 81s
rancher-webhook-5b5665c649-rsx9s 1/1 Running 0 4h30m修改后:
NAME READY STATUS RESTARTS AGE
cattle-cluster-agent-57ccdb69b4-9q7bl 1/1 Running 0 13s
cattle-cluster-agent-57ccdb69b4-p882r 1/1 Running 0 15s
rancher-webhook-5b5665c649-rsx9s 1/1 Running 0 4h35mAll Done.
等待几分钟,然后到 rancher 上查看集群状态,接下来就能进行应用和服务的部署啦。
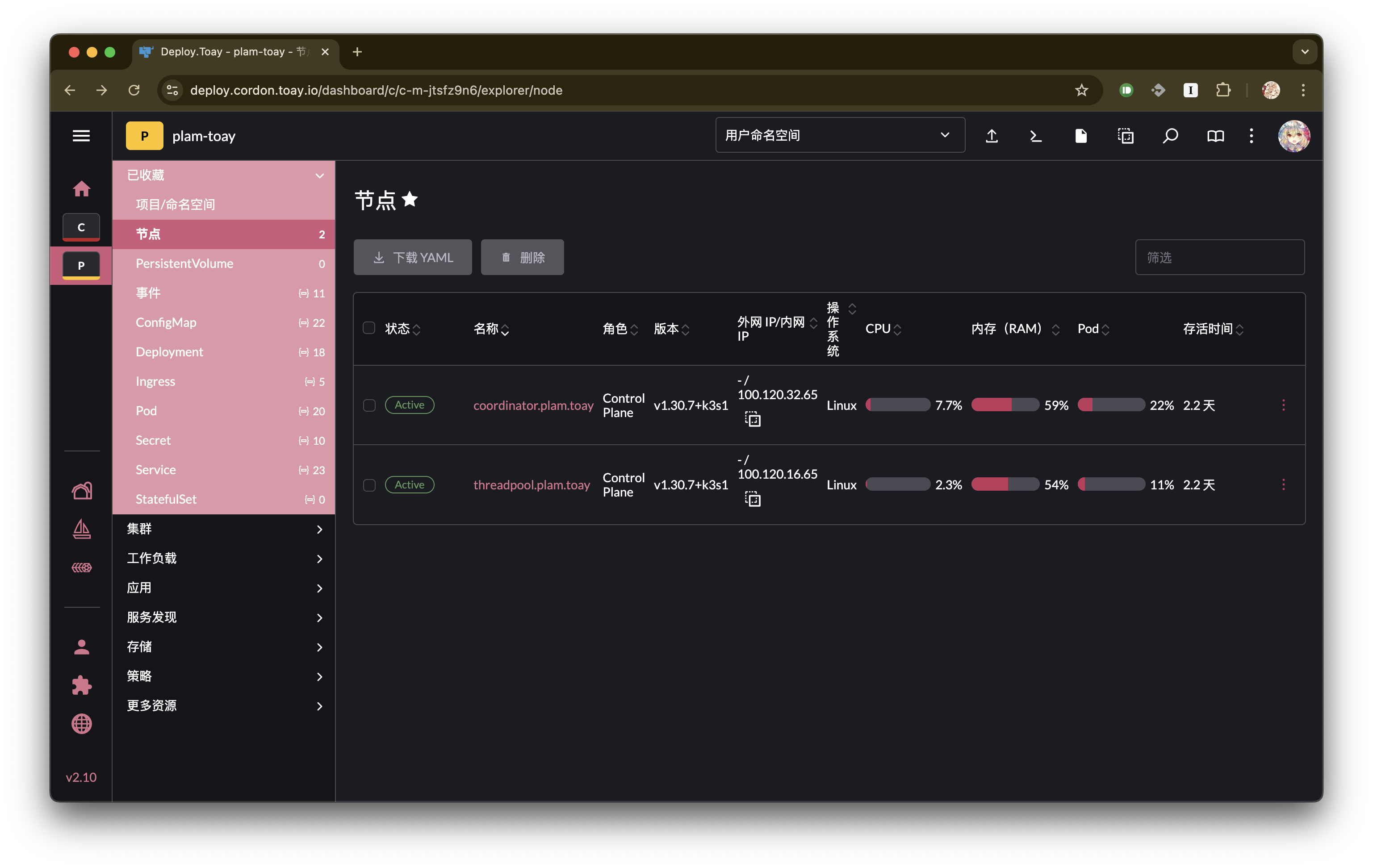
你也可以尝试使一个节点掉线,观察 k3s 能否正常地将服务转移至其他节点,毕竟这是我们搭建集群想要实现的最主要功能。
例如,实验室每天晚上都会断电,因此我一般会将 worker 部署到位于实验室主机中的虚拟机节点(threadpool.plam.toay)上。
当断电时,k3s 会自动对节点进行污点标记(node.kubernetes.io/unreachable=:NoSchedule 和 node.kubernetes.io/unreachable=:NoExecute):
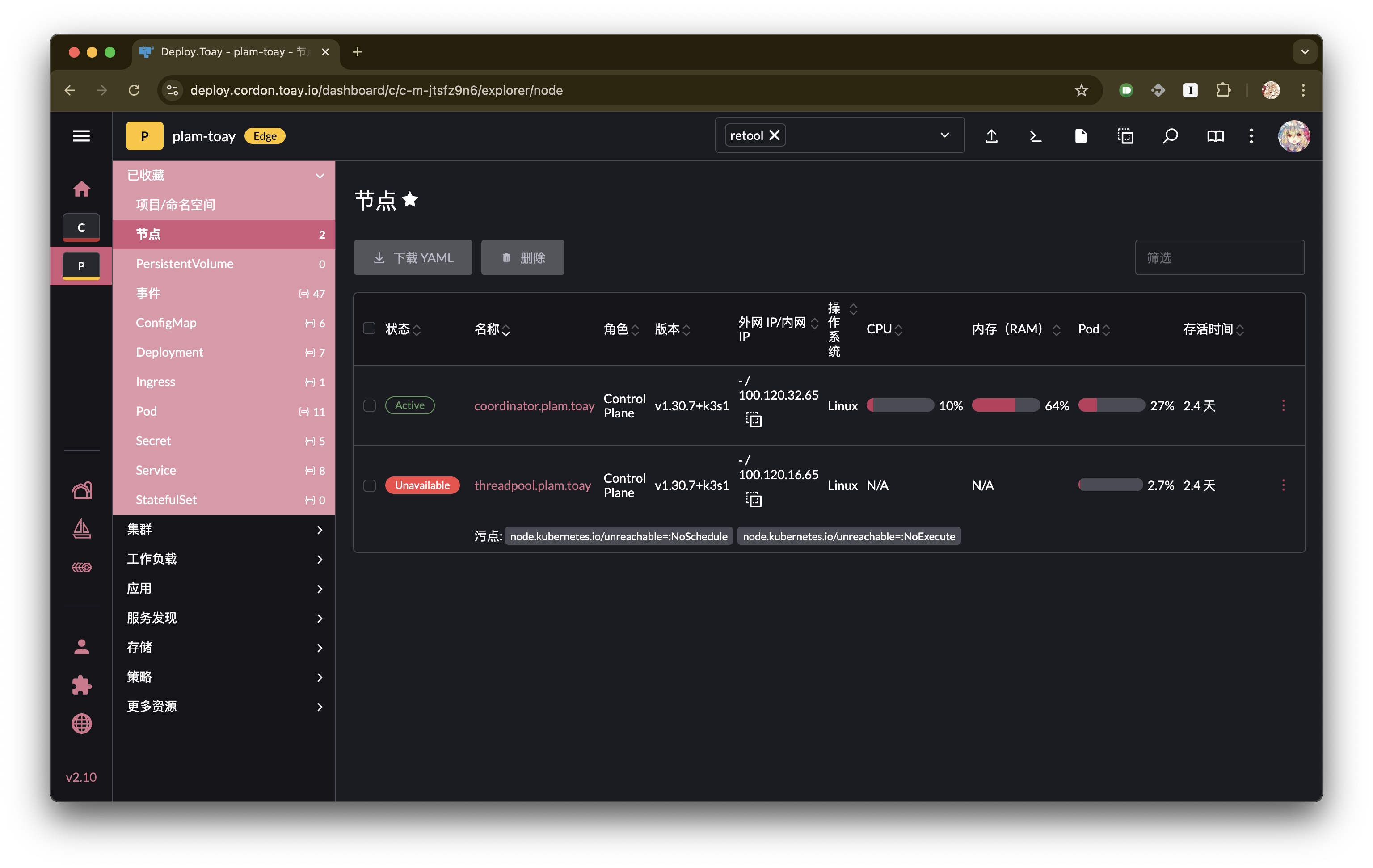
以及 pod 部署转移(threadpool.plam.toay => coordinator.plam.toay):
从而保证了服务的高可用。
关于后续对 k3s 集群维护的相关内容,我特意新建了一个专栏 k3s 集群维护笔记 来记录,欢迎关注😊。
Bonus
最后,Tailscale 实现了一些非常好用的便捷功能,这里简单做个摘要:
Taildrop
使用 Taildrop 可以非常方便地实现 Tailnet 中文件的传递,从此可以不再使用 SFTP 咯😋。
从 Linux 端发送:
tailscale file cp <src-file-loc> <dst-device>:然后从 Linux 端接收:
tailscale file get <dst-dir>Subnet Router
免费版仅有的一个 Subnet Router 也可以利用起来,通过一行命令实现从你的 Tailnet 访问 LAN 网中的所有设备:
sudo tailscale up advertise-routes=10.24.1.1/24使用 Exit Node
可以使用 Exit Node 来代理全部流量,实现一键接入完整互联网的功能:
Server 节点:
sudo tailscale up --advertise-exit-nodeClient 节点:
sudo tailscale up --exit-node=<exit-node-ip>目前 Tailscale 貌似还没打算实现复杂的分流功能😭。
若要跳过 局域网流量(仅 LAN 而已) 的代理,可添加 --exit-node-allow-lan-access=true 参数来实现。