
未完待续,目前正在折腾多线宽带叠加/分流,尽请期待完稿日。😊
本篇继续来记录 k3s 集群的基础设施维护。
接 上篇文章 完成了对宿舍设施的升级后,准备集中解决下几个痛点;总结起来就是(还是)网络问题。
集群网络问题
域控制器 与 主/从 DNS
DNS 作为集群中的基础,其稳定性保证各项服务的质量,因此需要一个良好易实施与维护的方案。
在这之前,我所有的域名都在 Cloudflare 上配置解析,其中也包括内网中的部分。在实际使用时就会发现这是不太方便的做法:将内网的服务地址往外暴露不仅配置麻烦,而且没有必要(暂且不说明安全方面也会有一定的隐患)。
因为现在有了 NAS,为了方便 SMB 共享的用户验证,我搭建了 Windows Server 用做 Active Directory 服务器的同时,发现域控本身就是在 DNS 基础上实现的,于是就顺便将域控的 DNS 用作集群的内部 DNS。当然也可以不使用 Windows Server 的 DNS 实现,而选择广泛使用的 bind9 作为替代;具体的做法就不在这里展开了。(熟悉嘛,直接抄的上篇文章😝)
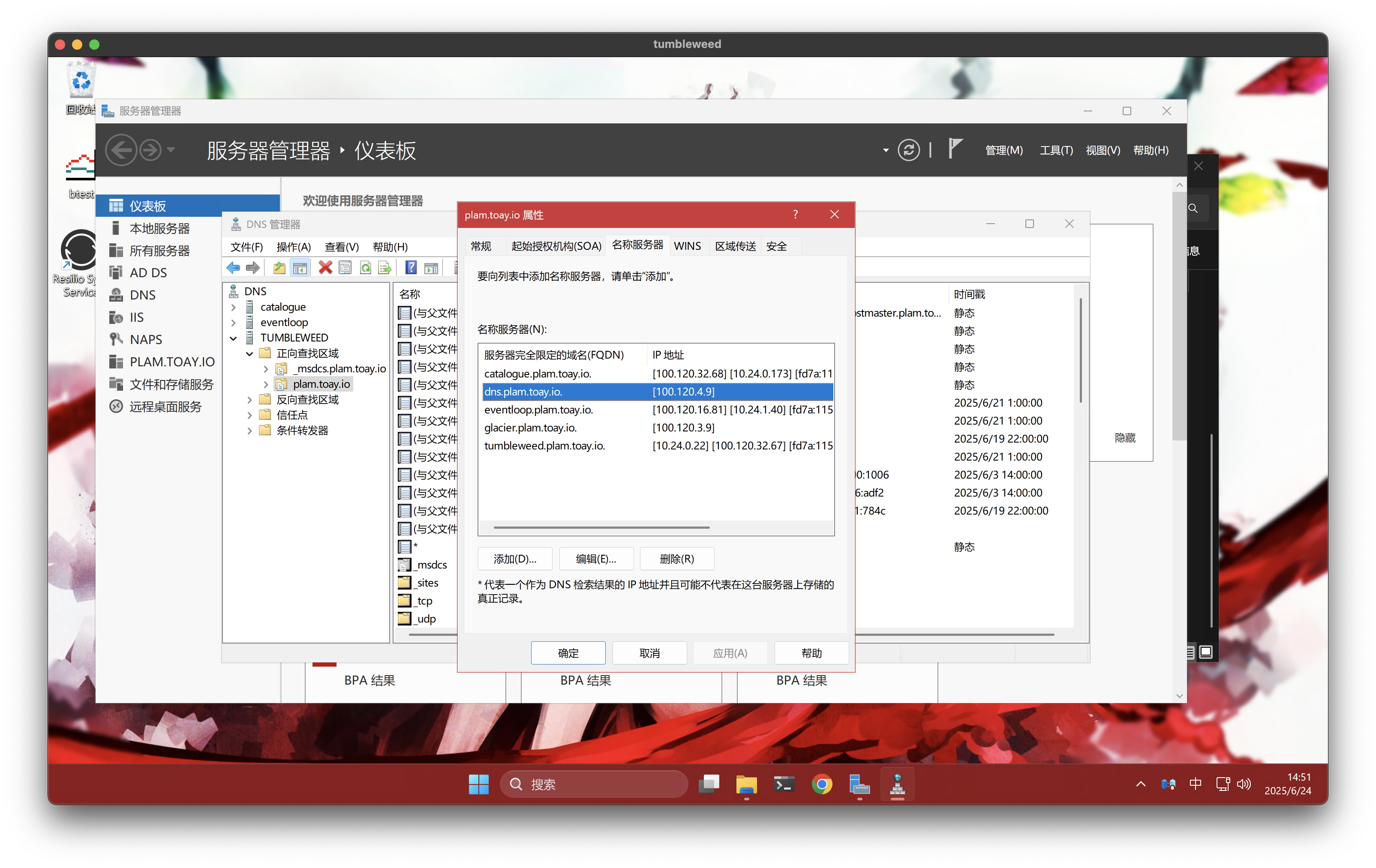
首先打开 DNS 管理器,将要配置为次级 DNS 的服务器解析记录(A/AAAA)添加到主 DNS 上,然后右键正向查找区域中的区域名称(例如我的域名为 plam.toay.io),在属性中的名称服务器选项卡中添加上次级 DNS 即可:
接着在将要用做次级 DNS 的 Linux 服务器上安装 Bind9:
apt install bind9 bind9utils bind9-doc编辑配置文件 /etc/bind/named.conf.options;先在 options 块中配置 listen-on 指定监听的 host:
options {
//...
listen-on {
100.120.4.9;
};
}后在文件末尾添加区域配置:
zone "plam.toay.io" { // Zone Domain
type slave;
masters {
100.120.32.67; // primary dns 1
100.120.32.68; // primary dns 2
};
allow-query { any; };
allow-notify {
100.120.32.67; // primary dns 1
100.120.32.68; // primary dns 2
};
notify no;
file "/var/lib/bind/slaves/plam.toay.io.hosts"; // slave hosts file
};systemctl restart bind9 重启 bind9 服务,就可以在日志中找到 zone transfer 的记录了。这时可使用 nslookup 尝试一下能否正常解析区域内的名称。
P.S. 1: 此时你可能会发现只有区域内的名称可以解析,因为目前的操作仅配置了 bind9 作为次级 DNS。如果要让它解析区域外的名称,还要额外配置转发。
在同一个配置文件中的 options 块里添加转发器:
options {
//...
forwarders {
8.8.8.8;
8.8.4.4;
};
recursion yes;
allow-recursion { any; };
allow-query { any; };
}转发作为默认配置,在具有显式配置的区域中不会生效,因此不会影响次级 DNS 的正常解析。
P.S. 2: 这里有一个小提示:当你在使用 Tailscale 的 exit-node 时,DNS 的解析是在 出口节点 上进行的。因此若使用 exit-node 的机器出现域名解析异常,可考虑从出口节点开始问题的排查。
如果你在 Tailscale 控制台中配置了下面的 DNS 自动分流的功能,这个问题可能就不会出现:
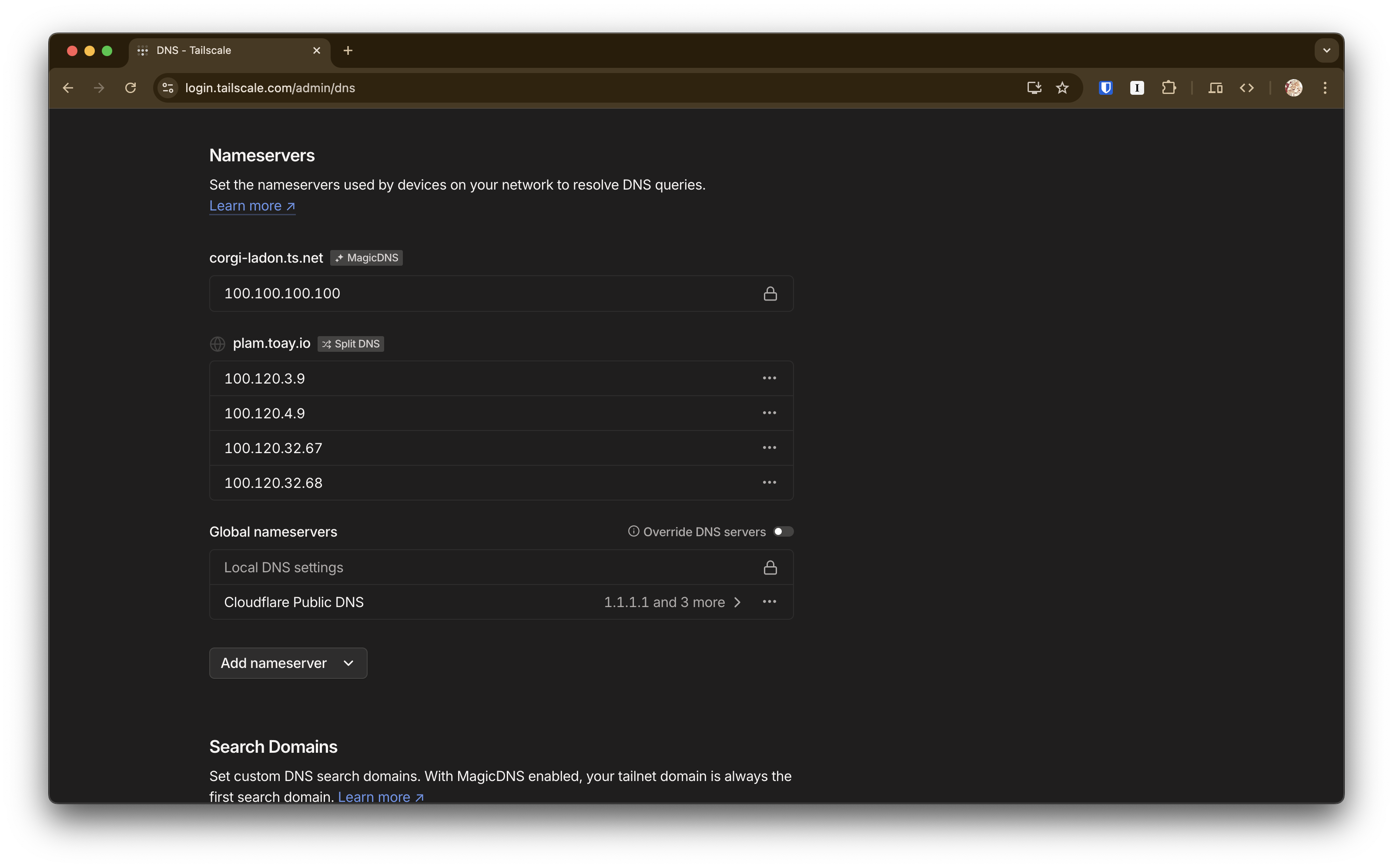
Tailscale 的客户端会在解析域名时自动将属于内网的部分发送至你配置的内网 DNS 上进行解析(因此叫做 Split DNS),你不再需要为要访问内网服务的设备手动配置内网 DNS 了。
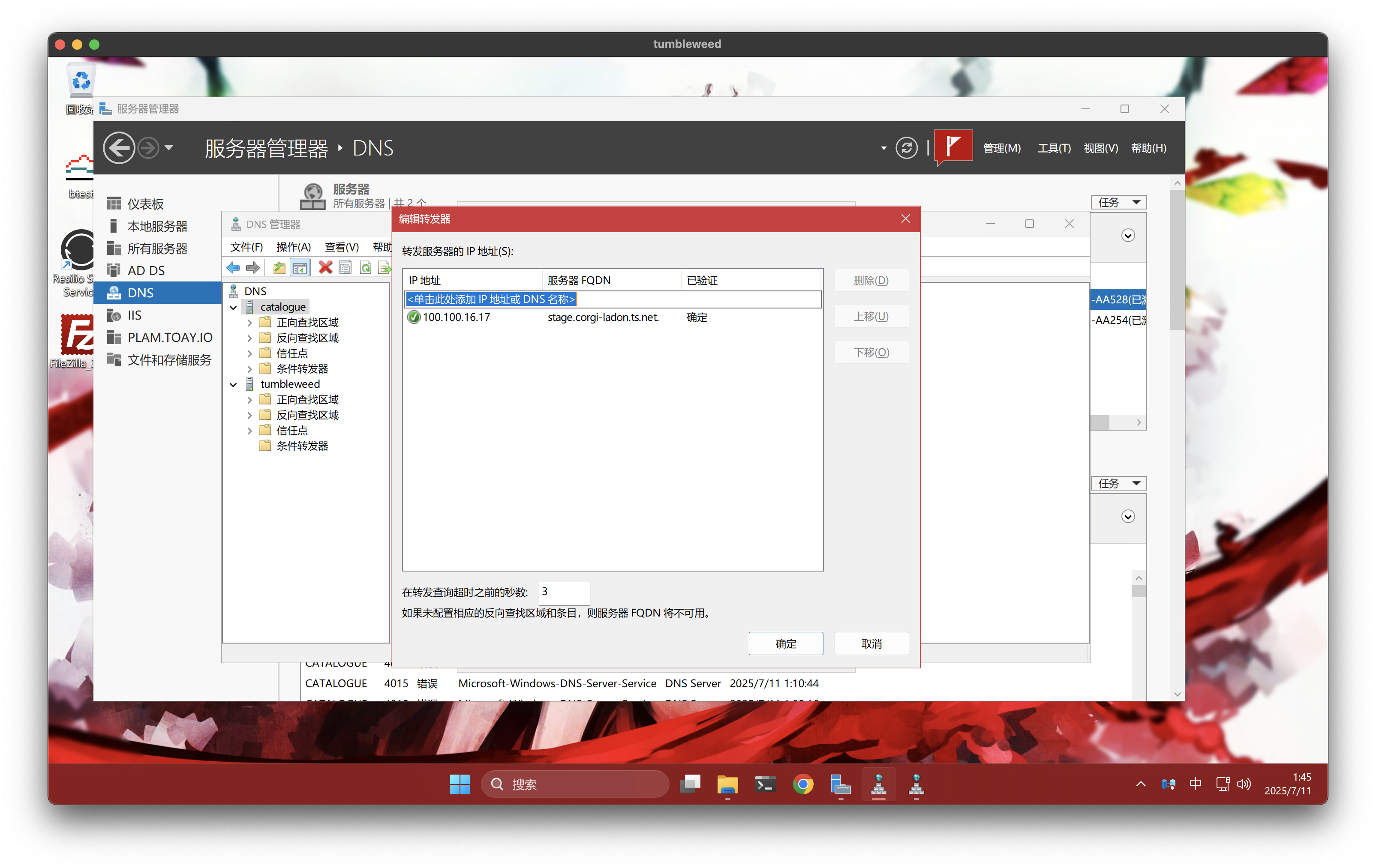
P.S. 3: 最后一个建议,对于大陆部署的服务器应当将域控 DNS 的上级配置为 可信 DNS (例如自建 DNS)上,避免部分机器没能使用到 Tailscale DNS 时遇到的域名污染问题。
当然,这个配置也是非常简单的啦:
PVE - Intel 网卡 大流量假死问题
PVE 总的来说非常稳定,之前的 PN61 连续 7*24 运行四五个月没有丝毫一点问题。
但是在最近更新最新系统后,在遇到大流量情况时会出现 intel 网卡假死的现象,具体来说就是物理机的网络完全断开,将网线拔下重插后立刻恢复;在 PVE 系统日志中可以找到以下的记录:
Jun 18 14:58:08 cubelets.plam.toay kernel: e1000e 0000:00:1f.6 eno1: Detected Hardware Unit Hang:
TDH <1d>
TDT <7a>
next_to_use <7a>
next_to_clean <1d>
buffer_info[next_to_clean]:
time_stamp <1326d01db>
next_to_watch <1e>
jiffies <138cb45c0>
next_to_watch.status <0>
MAC Status <40080083>
PHY Status <796d>
PHY 1000BASE-T Status <3c00>
PHY Extended Status <3000>
PCI Status <10>网上搜了下,在 PVE 的官方论坛上找到了 解决方法:关闭 ~~rx/tx checksumming~~
这个方法在生效一段时间后,
先使用 ethtool -k eno1 命令审查开启的选项,可以使用 grep 查找 checksumming 相关的配置:
~ ethtool -k eno1
Features for eno1:
rx-checksumming: on
tx-checksumming: on
tx-checksum-ipv4: off [fixed]
tx-checksum-ip-generic: on
tx-checksum-ipv6: off [fixed]
tx-checksum-fcoe-crc: off [fixed]
tx-checksum-sctp: off [fixed]
scatter-gather: on
tx-scatter-gather: on
tx-scatter-gather-fraglist: off [fixed]
...确认开启了校验后,可以使用下面的命令来关闭校验:
~ ethtool -K eno1 tx off rx off
Actual changes:
tx-checksum-ip-generic: off
tx-tcp-segmentation: off [not requested]
tx-tcp6-segmentation: off [not requested]
rx-checksum: off配置是立刻生效的,在这之后便不会在大流量时挂机了。然而配置在重启后会失效,因此需要额外的配置以在启动时应用。
根据官方论坛上 另一条帖子 的记录,可以编辑 /etc/network/interfaces 文件,在 iface eno1 inet manual 后添加一条 post up 命令 post-up /sbin/ethtool -K eno1 tx off rx off 即可。