
拥有一个能稳定运行的 k3s/k8s 集群可能并不太容易(所以这只会是一个系列中的一篇😝)。我将在这个系列中记录我爬坑的过程,既为我之后重建x,也为可能存在的读者作一定的参考。
对于文章中的内容,如果有错误,或是你有更好的方案,欢迎在文末提出。😊
网络
网络可以说是集群维护中最头痛的一件事了,特别是在大陆部署服务器时:国内服务器带宽小且贵,多数 registry、repository、api 不是太慢就是 connection reset、dns 污染。总之,部署在大陆的服务器有一个离不开的一个问题,如何让外网流量正常地进出?
之前我的方案是 使用 openwrt 作为软路由 的方式透明代理所有流量,但因为 clash 分流配置复杂存在内存泄漏需要定时重启、软路由会增加 Tailscale 直连难度等问题,最后现在选用 自建 dns + http/socks proxy via Tailscale 的方式,完美解决了长期的痛点。
DNS
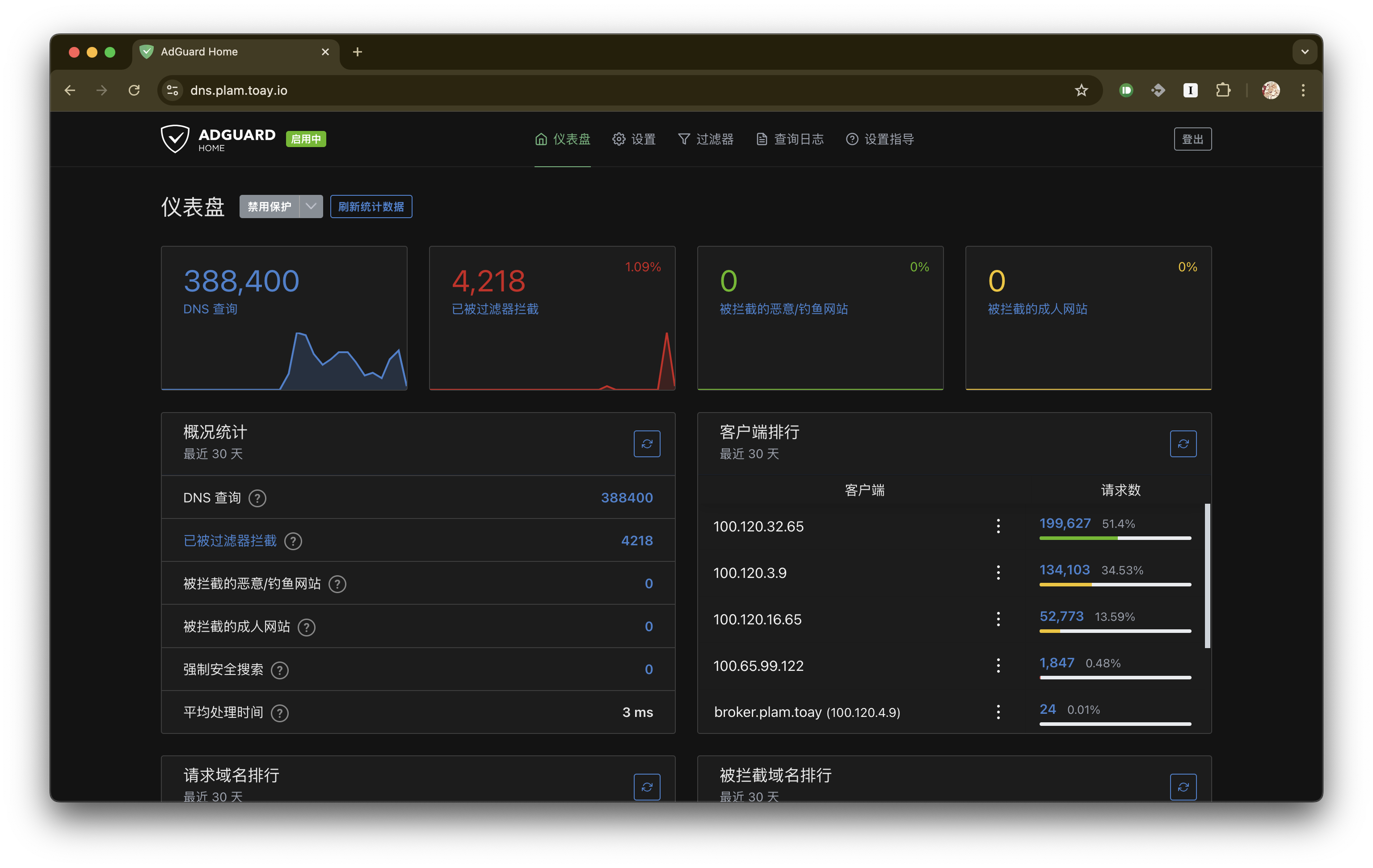
目前采用的方案是在国内服务器集群内多节点部署 AdGuard-Home (一般三个就足够了,而且用着还算稳定可靠),并指向 可信上游 dns (可在大陆外再搭一台只做上游,或仅使用 doh 然后把缓存拉满,运营商的那些统统丢掉),systemd-resolved 会自动 Failover,那在每台机器上都填完整就好了。
容器流量代理方案
现在得到正确的 ip 已有了可靠的保证,接下来就该部署代理了。
目前采用的方案是在 线路稍好 的国外服务器上部署一个 只 bind Tailnet 地址的 v2ray http/socks5 proxy(如果国外节点多的话可以用 nginx 做负载均衡),然后向需要用到代理的主机、容器什么的添加环境变量就好了。
为 k3s 容器添加环境变量最方便的方式为:单独将代理参数存入一个 configmap 中:
apiVersion: v1
data:
ALL_PROXY: socks5://<user>:<password>@<proxy-address>:<socks5-port>
HTTP_PROXY: http://<user>:<password>@<proxy-address>:<http-port>
HTTPS_PROXY: http://<user>:<password>@<proxy-address>:<http-port>
NO_PROXY: >-
.local, *.local, localhost, 127.0.0.0/8, 100.64.0.0/10, 10.42.0.0/16, 10.43.0.0/16
all_proxy: socks5://<user>:<password>@<proxy-address>:<socks5-port>
http_proxy: http://<user>:<password>@<proxy-address>:<http-port>
https_proxy: http://<user>:<password>@<proxy-address>:<http-port>
no_proxy: >-
.local, *.local, localhost, 127.0.0.0/8, 100.64.0.0/10, 10.42.0.0/16, 10.43.0.0/16
kind: ConfigMap 其中 NO_PROXY/no_proxy 将使下列目标绕过代理:
- .local, *.local: 集群域名
- localhost, 127.0.0.0/8: lo
- 100.64.0.0/10: Tailnet
- 10.42.0.0/16, 10.43.0.0/16: k3s 集群 pod cidr 和 service cidr
然后在创建 deployment 时引用这个 configmap 即可。
注意:
- 配置代理的环境变量共8条,最好一条都不少(不同的程序对大小写有不一样的要求¿)
- 使用代理参数后,所有没在 NO_PROXY/no_proxy 中出现的目标流量将经过代理;因此按照上述的配置后,容器内的服务需要使用完整的集群内域名以保证命中规则,例如 service
prometheus.prometheus应该使用prometheus.prometheus.svc.cluster.local - 大多数情况下可通过进入容器使用 curl -vvv 来判断是否走了代理,如下所示:
grafana-57968c8758-s9b52:/usr/share/grafana$ curl prometheus.prometheus.svc.cluster.local:9090 -vvv
07:55:46.701660 [0-x] == Info: [READ] client_reset, clear readers
07:55:46.701800 [0-x] == Info: Uses proxy env variable no_proxy == '.local, *.local, localhost, 127.0.0.0/8, 10.24.0.0/16, 100.64.0.0/10, 10.42.0.0/16, 10.43.0.0/16'
07:55:46.900827 [0-0] == Info: Host prometheus.prometheus.svc.cluster.local:9090 was resolved.
07:55:46.900978 [0-0] == Info: IPv6: (none)
07:55:46.901066 [0-0] == Info: IPv4: 10.43.110.251
07:55:46.901166 [0-0] == Info: [SETUP] added
07:55:46.901292 [0-0] == Info: Trying 10.43.110.251:9090...
07:55:46.901590 [0-0] == Info: Connected to prometheus.prometheus.svc.cluster.local (10.43.110.251) port 9090
07:55:46.901808 [0-0] == Info: using HTTP/1.x
07:55:46.902026 [0-0] => Send header, 108 bytes (0x6c)k3s datastore
之前 有强调过 k3s datastore 的重要性,然而当预算不足时只能在两个代价之间找平衡点。我给出的折中方案为 MariaDB Galera 集群,这里我将参考 官方文档,记录 典型三节点全主数据库集群 遇到一些常见情形时的 crash recovery 流程。
1:2 分裂
集群分裂大致是由网络掉线或电源中断造成:前者相较于后者,其掉线后可能还在继续写事务,即可能产生冲突。因此集群分裂后恢复时最主要的步骤是 确认拥有最新状态的节点,使用其作为 集群恢复的 bootstrap 节点 以便于其它节点能通过 Incremental State Transfer 来 以增量形式 同步状态。
最新状态序列号(recovery position state sequence)可通过 sudo -u mysql mysqld --wsrep-recover 命令来得到。
例如,通过在节点一执行上述命令,得到其 recovery position 为 3864673:
~ sudo -u mysql mysqld --wsrep-recover
2025-01-04 5:03:47 0 [Note] Starting MariaDB 10.11.8-MariaDB-0ubuntu0.24.04.1 source revision 3a069644682e336e445039e48baae9693f9a08ee as process 1272794
2025-01-04 5:03:47 0 [Note] InnoDB: Compressed tables use zlib 1.3
2025-01-04 5:03:47 0 [Note] InnoDB: Number of transaction pools: 1
2025-01-04 5:03:47 0 [Note] InnoDB: Using crc32 + pclmulqdq instructions
2025-01-04 5:03:47 0 [Note] InnoDB: Using liburing
2025-01-04 5:03:47 0 [Note] InnoDB: Initializing buffer pool, total size = 128.000MiB, chunk size = 2.000MiB
2025-01-04 5:03:47 0 [Note] InnoDB: Completed initialization of buffer pool
2025-01-04 5:03:47 0 [Note] InnoDB: File system buffers for log disabled (block size=512 bytes)
2025-01-04 5:03:47 0 [Note] InnoDB: End of log at LSN=8179900673
2025-01-04 5:03:47 0 [Note] InnoDB: 128 rollback segments are active.
2025-01-04 5:03:47 0 [Note] InnoDB: Setting file './ibtmp1' size to 12.000MiB. Physically writing the file full; Please wait ...
2025-01-04 5:03:47 0 [Note] InnoDB: File './ibtmp1' size is now 12.000MiB.
2025-01-04 5:03:47 0 [Note] InnoDB: log sequence number 8179900673; transaction id 7569239
2025-01-04 5:03:47 0 [Warning] InnoDB: Skipping buffer pool dump/restore during wsrep recovery.
2025-01-04 5:03:47 0 [Note] Plugin 'FEEDBACK' is disabled.
2025-01-04 5:03:47 0 [Warning] You need to use --log-bin to make --expire-logs-days or --binlog-expire-logs-seconds work.
2025-01-04 5:03:47 0 [Note] Server socket created on IP: '100.120.32.65'.
2025-01-04 5:03:47 0 [Note] WSREP: Recovered position: 93114f49-c453-11ef-b5ed-5b52f2d6eaa1:3864673节点二与节点一相同,而节点三为 3694624:
~ sudo -u mysql mysqld --wsrep-recover
2025-01-04 13:04:45 0 [Note] Starting MariaDB 10.11.8-MariaDB-0ubuntu0.24.04.1 source revision 3a069644682e336e445039e48baae9693f9a08ee as process 249409
2025-01-04 13:04:45 0 [Note] InnoDB: Compressed tables use zlib 1.3
2025-01-04 13:04:45 0 [Note] InnoDB: Number of transaction pools: 1
2025-01-04 13:04:45 0 [Note] InnoDB: Using crc32 + pclmulqdq instructions
2025-01-04 13:04:45 0 [Note] InnoDB: Using liburing
2025-01-04 13:04:45 0 [Note] InnoDB: Initializing buffer pool, total size = 128.000MiB, chunk size = 2.000MiB
2025-01-04 13:04:45 0 [Note] InnoDB: Completed initialization of buffer pool
2025-01-04 13:04:45 0 [Note] InnoDB: File system buffers for log disabled (block size=512 bytes)
2025-01-04 13:04:45 0 [Note] InnoDB: End of log at LSN=7281719277
2025-01-04 13:04:45 0 [Note] InnoDB: 128 rollback segments are active.
2025-01-04 13:04:45 0 [Note] InnoDB: Setting file './ibtmp1' size to 12.000MiB. Physically writing the file full; Please wait ...
2025-01-04 13:04:45 0 [Note] InnoDB: File './ibtmp1' size is now 12.000MiB.
2025-01-04 13:04:45 0 [Note] InnoDB: log sequence number 7281719277; transaction id 6622581
2025-01-04 13:04:45 0 [Warning] InnoDB: Skipping buffer pool dump/restore during wsrep recovery.
2025-01-04 13:04:45 0 [Note] Plugin 'FEEDBACK' is disabled.
2025-01-04 13:04:45 0 [Warning] You need to use --log-bin to make --expire-logs-days or --binlog-expire-logs-seconds work.
2025-01-04 13:04:45 0 [Note] Server socket created on IP: '100.120.3.9'.
2025-01-04 13:04:45 0 [Note] WSREP: Recovered position: 93114f49-c453-11ef-b5ed-5b52f2d6eaa1:3694624由于状态序列号 3694624 < 3864673,即节点三的状态没跟得上节点一与二(因为上述事例是因为节点三断电导致)。此时即可编辑 bootstrap 节点(即节点一或二)上的 /var/lib/mysql/grastate.dat 文件,将原本为 0 的 safe_to_bootstrap 改为 1(通过这个符号位阻止可能造成集群分裂的不安全的启动),然后执行 galera_new_cluster 来重置集群。
另外,若尝试拉起其它成员时出现类似于 [ERROR] WSREP: ./gcs/src/gcs.cpp:gcs_open():1668: Failed to open channel 'carton.toay' at 'gcomm://100.120.16.65,100.120.16.66,100.120.32.65,100.110.16.17,100.120.3.9': -110 (Connection timed out) 的情况时,可手动选取现在正在运行且已同步至最新状态的节点作为 bootstrap 节点来帮助还没拉起的成员恢复:
通过 sudo mysql 登录后执行 SET GLOBAL wsrep_provider_options='pc.bootstrap=true'; 来 手动使能 primary component;这时再重新 restart 就不会有问题了。
Monitoring
最后,为了能保证集群的稳定,在宕机之前做好监控与预警是有必要的。
以前使用过 ELK stack,虽然用起来非常舒服,但由于 elasticsearch 是做全文索引,还是用 memory hogger 写的,集群内外存的资源开销都过于庞大。因此最后换成了最开始就使用的 prometheus stack。
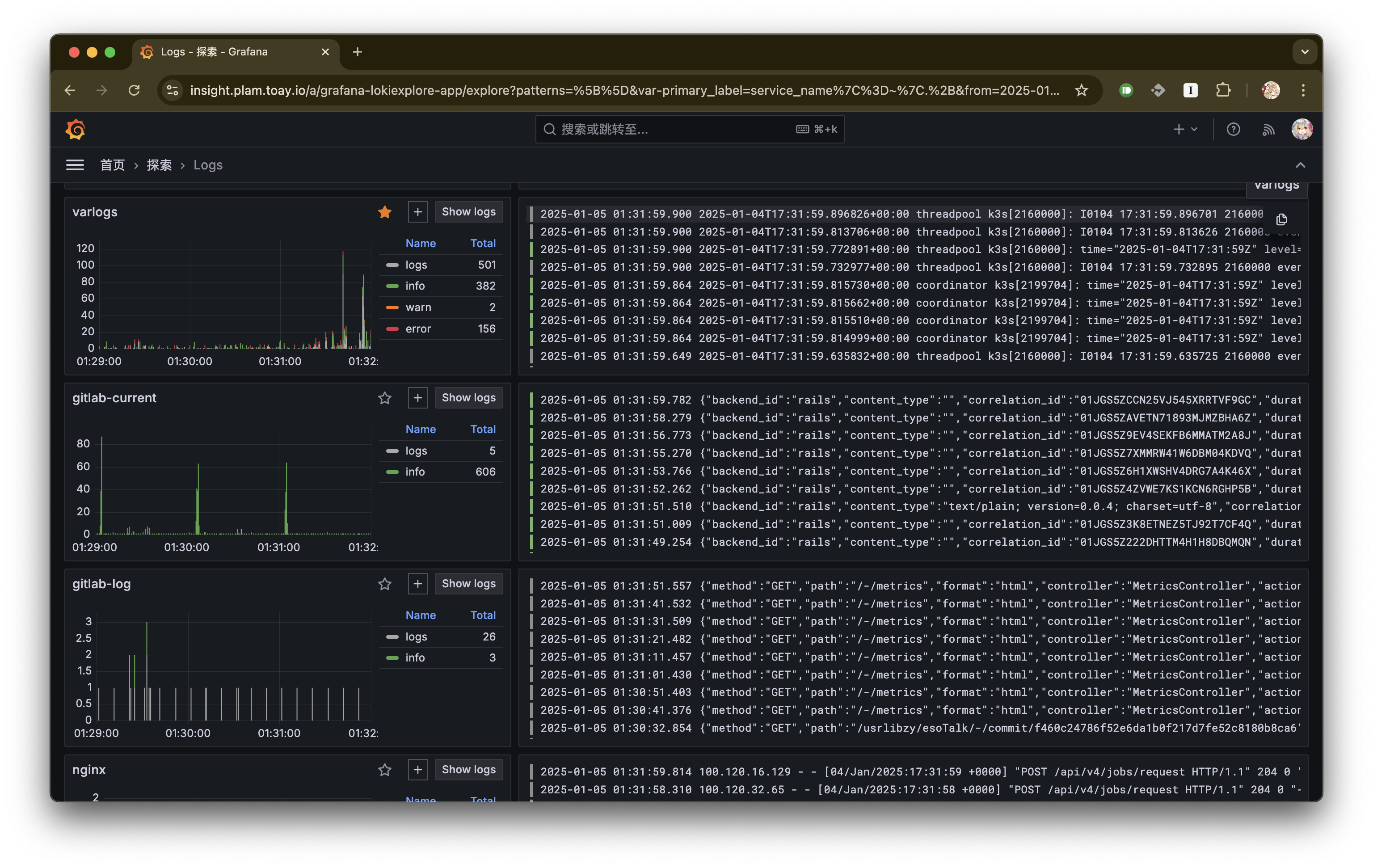
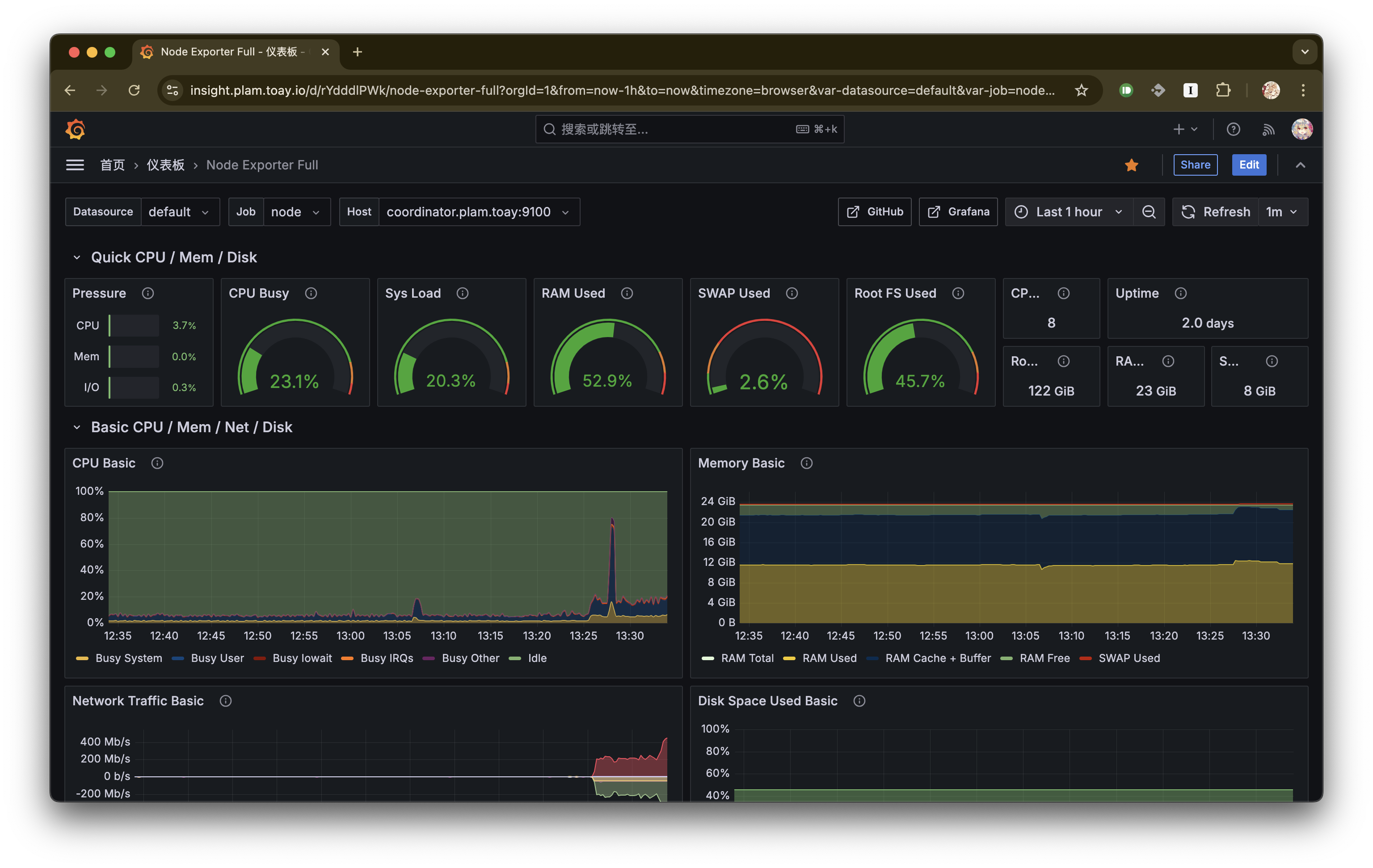
先给几张实际截图看看:
Grafana logs:
Grafana node metrics:
prometheus stack 的主要组成为:
- Grafana: 可视化 Web 应用
- Prometheus: 从 *_exporter 采集指标数据
- Loki: 日志数据采集
- *_exporter: 指标数据收集与统一 expose
- promtail: 收集与提交日志数据至 Loki
这个 stack 中只有 Grafana、Prometheus 和 Loki 集中部署,后两者部署在所有需要收集数据的机器上,类似于 elastic-agent;总体来说非常好安装啦。
对于 node_exporter 和 promtail 这两个 agent 来说,有个部署的小技巧:若要在集群内中的所有节点上均部署,可以在编写 deployment 时指定 pod 副本数为 节点数、pod 调度中指定 反亲和性拓扑键为 kubernetes.io/hostname,然后 k3s 会自动在每个节点上都部署一个 pod。下面是 deployment.yaml 中的一个示例片段:
spec:
replicas: 2
strategy:
type: Recreate
template:
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector: {}
topologyKey: kubernetes.io/hostname 对于 node_exporter 来说,需要使用 host network 而不是 service 来暴露服务,否则从不同节点端口采集到的都是相同的、来自任意 pod 的数据。